

AWS データ分析で川柳を解析!自然言語処理とテキストマイニングを試してみた話
AWS 認定インストラクターのたかやまです。
今年の2月に開催された弊社の企画、「トレノケートAWS川柳大賞」はお楽しみいただけましたか?
約1ヶ月に渡り、X やフォームからの応募を募ったところ 1,015 句(有効応募数)もの川柳が集まりました。
せっかく応募いただいたので、マーケの強い要望もありデータ分析を行いました。
全体の流れは、以前に Qiita に投稿しているのでそちらも併せてご覧ください。
目次[非表示]
- はじめに:AWS データ分析の目的とは?
- AWS データ分析に活用した主要サービス
- データの流れと全体アーキテクチャ
- AWS データ分析によるデータクレンジングの流れ
- Amazon Comprehend × Bedrock によるテキストマイニング
- 分析結果の活用とAWS データ分析の可能性
- AWS データ分析を賢く学ぶなら、トレノケートのAWS研修で
はじめに:AWS データ分析の目的とは?
「データ分析」と一言で言っても、目的によって手法は大きく変わります。今回のプロジェクトでは、AWS データ分析を活用して、マーケティングキャンペーンの投稿データを解析しました。
マーケティング担当からの要望は以下の通りです:
- 頻出キーワードを抽出したい
- 川柳の内容をネガポジ(感情)分類したい
- キーワードから関連する AWS サービスカテゴリを導きたい
- ワードクラウドで頻出度合いを視覚化したい
目的が明確になったことで、必要な分析手法と AWS サービスが見えてきました。
AWS データ分析に活用した主要サービス
今回、AWS川柳のデータ分析をするにあたり、主に3つのAWS データ分析サービスを活用しました。
Amazon Comprehend
Amazon Comprehend は、テキストデータから言語検出、キーフレーズ抽出、感情分析などが可能な自然言語処理(NLP)サービスです。事前学習をおこなう必要がなく、すぐに始められるのが特徴です。
テキストマイニングに向けて機械学習モデルを作ることもできますが、今回は、事前学習済みモデルを利用する Amazon Comprehend を採用しました。
参考:Amazon Comprehend(テキストのインサイトや関係性を検出)| AWS
医療分野に特化した Amazon Comprehend Medical というサービスもあります。
AWS Glue DataBrew
AWS Glue DataBrew は、実際のデータを確認しながらデータのクリーニングや正規化といった前処理を実行できるサービスです。
参考:ビジュアルデータ準備 - AWS Glue DataBrew - AWS
ノーコードでデータの前処理ができ、データのクリーニングや正規化を GUI 上で操作でき、分析前の準備に最適です。
Amazon Bedrock
Amazon Bedrockは、複数の生成AIモデル(Claude、Llamaなど)をAPIで簡単に利用できる AWS のサービスです。インフラ管理なしで、テキスト生成や分類、要約などの処理が可能です。
今回の分析では、抽出したキーワードを AWS サービスカテゴリに分類するのに活用しました。
参考:基盤モデルによる生成 AI アプリケーションの構築 - Amazon Bedrock - AWS
データの流れと全体アーキテクチャ
X(旧Twitter)からのデータとフォームから投稿されたデータは、マージされて CSV 形式で手元に届くようです。
しかし、X からのデータはハッシュタグをもとに抽出した生データになるので、川柳を含んでいないデータも含んでいました。また、川柳についても改行で区切られているものや、スペースで区切られているものなど様々です。

Amazon Comprehend と AWS Glue DataBrew を利用すれば望みのものが作れそうです。
ということで、以下のアーキテクチャを考えました。

AWS データ分析によるデータクレンジングの流れ
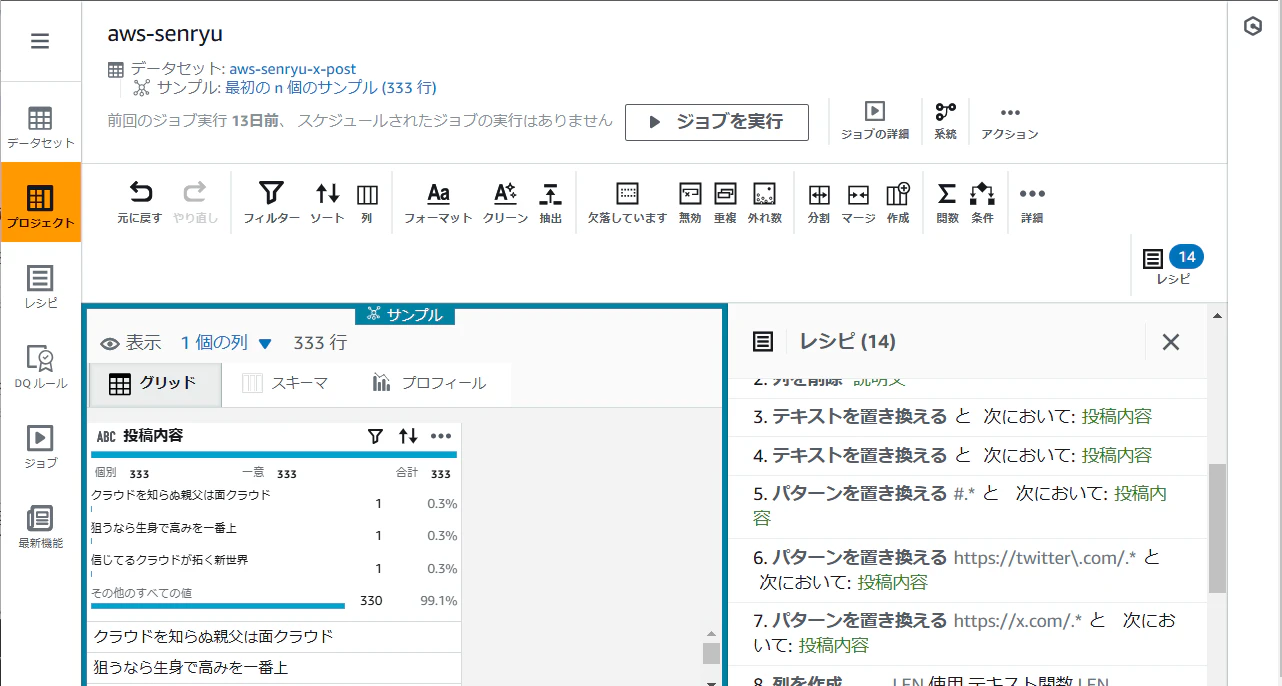
CSV データを AWS DataBrew に読み込ませてデータを確認します。
さて・・・どうしたものか。主に5つのステップを踏みました。
1. 不要なフィールドの除去
X からエクスポートされたデータは、投稿内容だけではなくアカウント名や時間など、不要なフィールドが多いです。まずは、これらを取り除いて取り扱うデータを少なくすることから始めました。
AWS Glue DataBrew で「列の削除」をおこない、川柳が含まれている列と投稿者の情報だけにしました。
| - Action: Operation: DELETE Parameters: sourceColumns: >- ["事務局選定作品2","髙山さん3","山下さん4","久保玉井さん5","再考余地あり","最終","除外","gyosyu_shokusyu_for_senryu","email","company","busyo","投稿日時(Conversion Date)","場所","説明文","非公開","認証済み","フォロー","フォロワー","投稿","いいね","リスト","最新投稿日時","X(Twitter)開始日時","ユーザーID","プロフィールURL","Profile","プロフィール画像URL","デフォルト画像","プロフィールウェブサイト","肩書き","投稿内容","投稿ID","投稿URL","リンク","投稿日時2","返信元投稿ID","ソース","アクティビティタイプ","返信内容","引用内容","投稿への反応日時","反応先の投稿ID","フォローした日時","フォロー元","フォロー解除した日時","フォロー解除元","フォローされた日時","フォロー解除された日時","事務局選定作品54","髙山さん55","山下さん56","久保玉井さん57","_c58","_c59","_c60","_c61","_c62","_c63","_c64","_c65","_c66","_c67","_c68","_c69","_c70","方法"] |
2. Null 値のデータと重複データの削除
次に、川柳が含まれていない行を削除します。なんで含まれていないのか?謎ですね。また、重複応募も散見されるので、重複したデータは 1 つのデータにまとめるため削除します。
AWS Glue DataBrew では、よく利用するようなアクションはすでに用意されているので、コードを書かずとも利用したアクションをレシピに加えるだけで使えます。
| - Action: Operation: REMOVE_MISSING Parameters: sourceColumn: 川柳作品 - Action: Operation: DELETE_DUPLICATE_ROWS Parameters: duplicateRowsCount: '2' |
3. 不要なテキストの除去
こちらがわかりやすくしてくれているのだと思いますが、川柳が【】の中に入っていたり、()の中に入っていたりします。また、改行で区切られたデータがあります。これも消してしまいましょう。
正規表現を利用した文字の削除が 1 回のアクションでは実行することができなかったので、一旦対象となる文字を別の文字列に置き換えてから、置き換えられた文字列を消すことにしました。(このあたり、もっといい方法あります?)
| - Action: Operation: REPLACE_TEXT Parameters: pattern: 【 sourceColumn: 川柳作品 - Action: Operation: REPLACE_TEXT Parameters: pattern: 】 sourceColumn: 川柳作品 - Action: Operation: REPLACE_PATTERN Parameters: pattern: (.*) sourceColumn: 川柳作品 value: '@@@' - Action: Operation: REPLACE_PATTERN Parameters: pattern: \\r\\n sourceColumn: 川柳作品 value: '@@@' - Action: Operation: REMOVE_COMBINED Parameters: collapseConsecutiveWhitespace: 'false' customValue: '@@@' removeAllPunctuation: 'false' removeAllQuotes: 'false' removeAllWhitespace: 'false' removeCustomCharacters: 'false' removeCustomValue: 'true' removeLeadingAndTrailingPunctuation: 'false' removeLeadingAndTrailingQuotes: 'false' removeLeadingAndTrailingWhitespace: 'false' removeLetters: 'false' removeNumbers: 'false' removeSpecialCharacters: 'false' sourceColumn: 川柳作品 |
4. 川柳かどうかの判定
川柳は、基本的に 5・7・5 の形式です。が、合ってないデータもあります。また、宣伝や感想なども紛れ込んでいました。
どのデータが川柳なのかを判定し、そうじゃないものと判断したものはバッサリ削ります。
まずは、前後のスペースを消してから LEN 関数を用いて文字列の長さを新しいフィールドにします。そのうえで、特定の文字列以上のデータは弾きます。
では、何文字にするのか。AWS DataBrew では、アクション実行後のプレビューが見れますので、いくつか試した結果 35 文字くらいでデータが抽出できそうでした。
| - Action: Operation: TRIM Parameters: endPosition: NaN functionStepType: TRIM ignoreCase: 'false' sourceColumn: 川柳作品 startPosition: NaN targetColumn: haiku - Action: Operation: LEN Parameters: endPosition: NaN functionStepType: LEN ignoreCase: 'false' sourceColumn: haiku startPosition: NaN targetColumn: _____TRIM_LEN - Action: Operation: REMOVE_VALUES Parameters: sourceColumn: _____TRIM_LEN ConditionExpressions: - Condition: IS_NOT_BETWEEN Value: '{"greaterThanEqual":"1","lessThanEqual":"35"}' TargetColumn: _____TRIM_LEN |
5. 不要なフィールドの削除
データ抽出だけに使ったフィールドは削除してきれいにします。
| - Action: Operation: DELETE Parameters: sourceColumns: '["_____TRIM_LEN","川柳作品"]' |
出来上がったレシピを利用して実際のデータに適用し、分析対象となるデータを抽出することに成功しました。
-------------------------
AWS にはたくさんのAWS データ分析サービスがあり、各サービスを組み合わせることで実践的なデータ分析が可能になります。こうしたスキルを体系的に学びたい方には、弊社のAWS認定トレーニングがおススメです。
バウチャ付きのコースもあり、AWS認定と取得も含めて効率よく学習できます。
Building Modern Data Analytics Solutions on AWS | IT研修のトレノケート
Building Modern Data Analytics Solutions on AWS (バウチャ付) | IT研修のトレノケート
Amazon Comprehend × Bedrock によるテキストマイニング
最終的にデータマイニングには、Comprehend と Bedrock を利用しました。Comprehend でキーワードの抽出と感情分析をおこない、Bedrock で AWS サービス名と思われるキーワードがどの AWS カテゴリなのかを考えてもらいました。
当初は全データを一括処理しようとしましたが、件数が多すぎて Bedrock がタイムアウト。そこで、15件ずつ分割して処理しました。
|
import json
import os
import logging
import boto3
import unicodedata
import pandas as pd
import io
# Set up the logger
logger = logging.getLogger()
logger.setLevel(logging.INFO)
# Set up constants
SENTENCE_BATCH_SIZE = 15 # Number of sentences to process in each batch
MODEL_ID = 'amazon.nova-lite-v1:0'
# Create AWS service clients.
s3 = boto3.resource('s3')
s3_client = s3.meta.client
comprehend_client = boto3.client('comprehend')
bedrock_client = boto3.client('bedrock-runtime', region_name="us-east-1")
# Retrieve S3 bucket and prefix settings from environment variables.
bucket_name = os.environ['S3_BUCKET_NAME']
prefix = os.environ['S3_PREFIX']
report_prefix = os.environ['S3_REPORT_PREFIX']
logger.info(f"Bucket Name: {bucket_name}, Prefix: {prefix}, Report Prefix: {report_prefix}")
def process_detect_aws_service_categories(sentences, categories):
"""
Process a batch of sentences using AWS Bedrock to detect AWS service categories.
:param sentences: List of sentences to analyze.
:param categories Dictionary to store category counts.
"""
if not sentences:
return
# Create a prompt for AWS Bedrock to analyze AWS service categories.
prompt_header = (
"以下のデータの中から、AWS のサービス名と思われるものを抽出し、所属する AWS サービスカテゴリを調べてください。"
"各サービスカテゴリごとに集計してください。\\n"
"出力はCSV形式で列は「サービスカテゴリ名、集計値」です。CSV形式のデータ以外は出力しないでください。\\n"
"サービスカテゴリ名は、ダブルクォーテーションで囲みます。\\n"
"サービスカテゴリ名は英語表記にしてください。\\n\\n"
"# 出力例\\n"
"\\"Compute, 1\\"\\n"
"\\"Storage, 10\\"\\n\\n"
"# データ\\n"
)
prompt = prompt_header + "\\n".join(sentences)
# Build the payload for the Bedrock model invocation.
request_payload = {
"messages": [
{
"role": "user",
"content": [{"text": prompt}]
}
],
"inferenceConfig": {
"maxTokens": 256,
"stopSequences": [],
"temperature": 0.7,
"topP": 0.9
}
}
# Invoke the Bedrock model.
response = bedrock_client.invoke_model(
body=json.dumps(request_payload),
modelId=MODEL_ID,
accept='application/json',
contentType='application/json'
)
response_body = response['body'].read().decode('utf-8')
generated_response = json.loads(response_body)
generated_csv = generated_response['output']['message']['content'][0]['text']
logger.info(f"Generated CSV: {generated_csv}")
# Process the generated CSV by removing the first and last lines, then add a header.
lines = generated_csv.splitlines()
if len(lines) > 2:
processed_csv = "\\n".join(lines[1:-1])
else:
processed_csv = generated_csv
df = pd.read_csv(io.StringIO(processed_csv))
for row in df.itertuples():
category = row[1].strip('"')
count = row[2]
if count == 0:
continue
categories.setdefault(category, 0)
categories[category] += count
def process_sentences_batch(sentences, emotions, key_phrases):
"""
Process a batch of sentences using AWS Comprehend to detect sentiment and key phrases.
:param sentences: List of sentences to analyze.
:param emotions: Dictionary to store sentiment counts.
:param key_phrases: Dictionary to store key phrase counts.
"""
if not sentences:
return
logger.info(f"Processing a batch of {len(sentences)} sentences.")
# Detect sentiments for the batch of sentences.
sentiment_response = comprehend_client.batch_detect_sentiment(
TextList=sentences, LanguageCode='ja'
)
for result in sentiment_response['ResultList']:
sentiment = result['Sentiment'].capitalize()
# Extract the sentiment score and round it to one decimal place.
sentiment_score = float(result['SentimentScore'][sentiment])
rounded_score = str(round(sentiment_score, 1))
emotions.setdefault(sentiment, {})
emotions[sentiment][rounded_score] = emotions[sentiment].get(rounded_score, 0) + 1
# Detect key phrases for the batch of sentences.
key_phrase_response = comprehend_client.batch_detect_key_phrases(
TextList=sentences, LanguageCode='ja'
)
for result in key_phrase_response['ResultList']:
for phrase_data in result['KeyPhrases']:
# Normalize the key phrase (convert full-width to half-width characters)
phrase = unicodedata.normalize('NFKC', phrase_data['Text'])
key_phrases[phrase] = key_phrases.get(phrase, 0) + 1
def write_csv_to_s3(s3_key, csv_content):
"""
Encode CSV content to cp932 and write it to S3.
:param s3_key: S3 object key (path) for the CSV file.
:param csv_content: CSV content as a string.
"""
encoded_csv = csv_content.encode('cp932', 'ignore')
s3_client.put_object(Bucket=bucket_name, Key=s3_key, Body=encoded_csv)
logger.info(f"CSV file written to s3://{bucket_name}/{s3_key}")
def lambda_handler(event, context):
# Initialize lists and dictionaries for storing haikus, key phrases, sentences, and emotions.
haikus = []
key_phrases = {}
emotions = {}
sentences = []
categories = {}
# Loop through S3 objects with the given prefix.
bucket = s3.Bucket(bucket_name)
for obj in bucket.objects.filter(Prefix=prefix):
# Extract the file name and determine the local file path.
file_name = obj.key.split('/')[-1]
file_path = f"/tmp/{file_name}"
logger.info(f"Processing file: {file_name}, Local path: {file_path}")
# Download the file from S3.
bucket.download_file(obj.key, file_path)
# Load the file as a CSV, assuming it contains a column named 'haiku'.
df = pd.read_csv(file_path, header=0, names=['haiku','lastname','firstname','x_account','pen_name'])
# Remove caridge returns and newlines from the haiku text.
df['haiku'] = df['haiku'].str.replace('\\r\\n', '\\n', regex=True)
df['haiku'] = df['haiku'].str.replace('\\n', '', regex=True)
for _, row in df.iterrows():
# Normalize the haiku text (convert full-width characters to half-width)
haiku_text = unicodedata.normalize('NFKC', row['haiku'])
haikus.append(haiku_text)
sentences.append(haiku_text)
# Process sentences in batches of 15 for sentiment and key phrase analysis.
if len(sentences) == SENTENCE_BATCH_SIZE:
process_sentences_batch(sentences, emotions, key_phrases)
process_detect_aws_service_categories(sentences, categories)
sentences = []
# Process any remaining sentences that didn't form a complete batch.
if sentences:
process_sentences_batch(sentences, emotions, key_phrases)
# Generate CSV content for key phrases and upload to S3.
key_phrase_csv = "key_phrase,count\\n" + "".join(
f"{phrase},{count}\\n" for phrase, count in key_phrases.items()
)
write_csv_to_s3(f"{report_prefix}/key_phrases.csv", key_phrase_csv)
# Generate CSV content for sentiment analysis and upload to S3.
sentiment_csv = "sentiment,score,count\\n"
for sentiment, score_dict in emotions.items():
for score, count in score_dict.items():
sentiment_csv += f"{sentiment},{score},{count}\\n"
write_csv_to_s3(f"{report_prefix}/sentimental.csv", sentiment_csv)
# Generate CSV content for haiku and upload to S3.
haiku_csv = "haiku\\n" + "".join(
f"{haiku}\\n" for haiku in haikus
)
write_csv_to_s3(f"{report_prefix}/haiku.csv", haiku_csv)
# Generate CSV content for AWS service categories and upload to S3.
categories_csv = "category,count\\n"
for category, count in categories.items():
categories_csv += f"{category},{count}\\n"
write_csv_to_s3(f"{report_prefix}/services.csv", categories_csv)
# Return a success response.
return {
'statusCode': 200,
'body': json.dumps('Finished analyze. Result has been written to S3')
}
|
Amazon Q Developer を利用し、基になるコードを書いてからリファクタリングしてもらいました。
関数のコメントまで付けてくれてありがたいですね。
分析結果の活用とAWS データ分析の可能性
今回のプロジェクトでは、AWS のデータ分析サービスを活用して、川柳キャンペーンの投稿データを効率的に処理・分析しました。
生のデータには改行や記号、重複などさまざまなクセがありましたが、そんなことを忘れさせるくらい楽しい作業でしたし、Glue DataBrew や Comprehend、Bedrock などのサービスを組み合わせることで、スムーズに価値ある情報を抽出することができました。
処理されたデータは、マーケティング担当によってデザインされたキャンペーンページに活用され、投稿者の想いがより魅力的に伝わる形で公開されました。
AWS データ分析は、マーケティングの可能性を広げるだけでなく、エンジニアにとっても実践的なスキルを磨ける強力なツールです。
また、来年も開催したいですね。そうすれば今年のデータとの比較もできますね。
AWS データ分析を賢く学ぶなら、トレノケートのAWS研修で
今回のプロジェクトでは、AWS のデータ分析サービスを活用して、川柳キャンペーンの投稿データをうまく整理・分析することができました。
生のデータにはいろんなクセがありますが、それをひとつずつ整えていく作業は、意外と楽しくて奥が深いものです。
「もっと AWS のデータ分析について学んでみたい」「実務でも使えるスキルを身につけたい」と感じた方には、弊社のAWS認定トレーニングがおススメです。
▼AWS のデータ分析について学びたい方は、Building Modern Data Analytics Solutions on AWS で
!
データレイク、データウェアハウス、ストリーミング分析、バッチ分析の4つの手法を4日で学ぶ研修です。
データエンジニアを目指す方にもおすすめです。
バウチャ付きのコースもあるので、学びながら資格取得も目指せますよ。
Building Modern Data Analytics Solutions on AWS | IT研修のトレノケート
Building Modern Data Analytics Solutions on AWS (バウチャ付) | IT研修のトレノケート
▼実践スキルを磨くなら、AWS Technical Essentials で !
実機演習が中心の研修です。仕事で構築作業を行う方や、シナリオベースの演習を通じて、実際に手を動かしながら各サービスの特徴を学びたい方におすすめのAWS研修です。
AWS Technical Essentials | IT研修のトレノケート
トレノケートのAWS認定トレーニングでは、AWS社の厳格なテクニカルスキル及びティーチングスキルチェックに合格した認定トレーナーがコースを担当します。AWS初心者向けの研修や、AWS認定資格を目指す人向けの研修をご提供し、皆様のAWS知識修得のサポートをいたします。
・トレノケートのAWS研修(AWS認定トレーニング)はこちら
いきなりの有償コースに抵抗がある方やまずはお試しをしてみたい方は、トレノケートが実施している無料セミナーがおすすめです。詳細はセミナーページよりご確認ください。
▼無料セミナーの詳細はこちらから



-1.webp)




















