

【推し活×AWS】Amazon Bedrock AgentCore Runtime で構築する"愛"のサーバレスアーキテクチャ
こんにちは!好きなラーメンは二郎系!
AWS認定講師の久保玉井です。
突然ですが、皆さんは推し活していますか?
私はX(旧Twitter)で「ほくほくいも丸くん」というXのBotを運用し、推しアイドルの活動を日々広める事に勤しんでいます。
これ↓がAWS Lambdaを使って立ち上げたボット
しかし、従来のAWS Lambda単体の実装では、「推しの尊さをLambda関数の if文の分岐だけで表現する」ことに限界を感じていました。
そこで今回、 Amazon Bedrock AgentCore Runtime と Strands フレームワークを導入し、 「推しの解像度(キャラクター性)」をエンジニアリングで解決する アーキテクチャへと刷新しました。
本記事では、その技術選定の裏側と、 「推しへの愛」をコードに落とし込むための実装 を紹介します。
ではさっそく見ていきましょう!
目次
はじめに
少し前から #びっくえんじぇる というアイドルグループを私は応援しておりまして、そのメンバーの中に最推しの 甘木ジュリさんという方がいます。
ちょうどXのDeveloper Consoleで「APIの利用料金が前もって少額チャージして使える!」 となったので以下対応することにしました。
たまごっちみたいなアイドルといっしょに成長するXのBotを作ろう!
普通推し活ってライブ行ったり、グッズ買ったりするじゃないですか?
でも私は技術者なんで、他とは違う推し活ができるなと前々から思ってました。やりたかった事としては「アイドルといっしょに成長するたまごっちみたいなボット」を作りたい!
そして推しの活動を広めたい支援したいってことで以下作りました。
もちろん各種規約類を十分に審議確認済みで作成してます。
Xのボットはどういう風に動いているのか?
ではXのボット。どういう構成で動いているかです。
実はその構成はXの記事で作成し公開しています。
AWS Serverless × Bedrockで「推し育成ボット」を作った話(DQ3風レベル上げ機能付き)

ポイントは推しの投稿や所属するグループの投稿内容、またはボット自体の活動によって経験値を獲得して成長していく内容です。ドラゴンクエストみたいにレベルアップしていくんですね♪
ポップな構成図

以下Githubにもコード載せています↓
https://github.com/maijun2/x-oshi-training-bot
問題と解決策
実際にボットが完成し利用してみたのですが、いくつか問題があることが判りました
if文では愛は語れない
例えばLambda関数の中でBedrock APIを叩いて処理をする場合、以下のような高度なタスクを実行しようとすると問題が出てきます。
「推しの動画を探し出してきて、翻訳し、その魅力をXのボットに投稿させる」
検索、要約、翻訳といった複数のツールを動的に使い分けるロジックをif文の羅列で書くには流石に限界があります。
- 「推しのXのポスト内容を分析して検索キーワードを選定する」
- 「検索結果が0件なら検索ワードを変えて検索してみる」
- 「翻訳が不自然ならやり直す」
こういう自律的な行動をすべて条件分岐でコーディングするのは無理です。
「自律的に思考し、行動し、自己修正する」
こういったAIエージェント的に動作させる必要があります。
AgentCore Runtimeで解決しよう!
複雑な処理の連鎖(チェーン)を行うならば、LangChainが有名です。自分で実装して動かすのは良いのですがEC2などで動作させるとなるとインフラのメンテナンスが必要になります。
しかしAIエージェントを利用できるサーバレスなサービスがAWSにはあるんです。
そう!Amazon Bedrock AgentCore Runtimeです。
開発したAIエージェントをホスティングできるんですね(引用元:AWS Setupブログより)
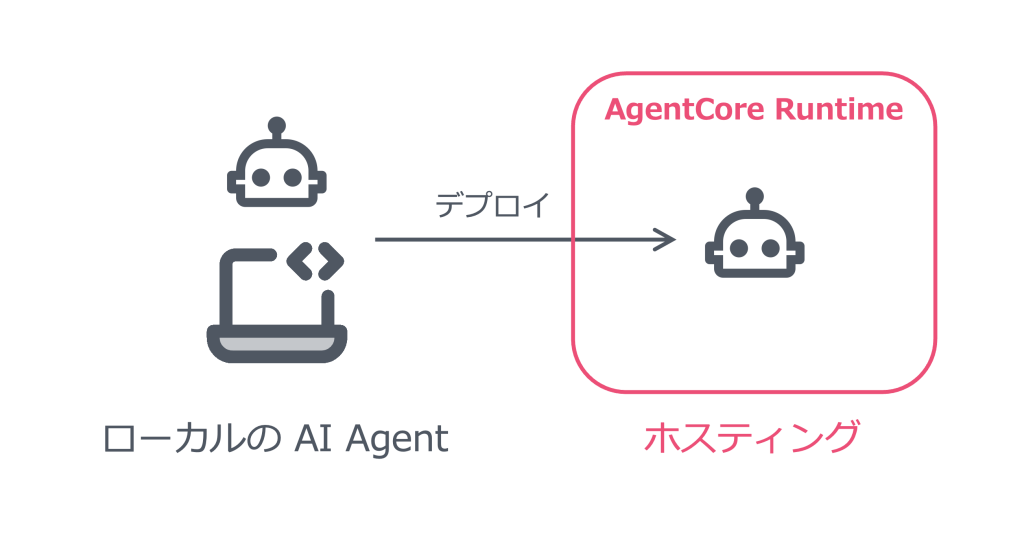
参考:5分で AI エージェントをデプロイ・ホスティングする – Amazon Bedrock AgentCore Runtime
しかもサーバレスなので未使用時には金額も押さえられるというお財布にも優しいサービスですラブ。
具体的なアーキテクチャ構成
では今回の構成です。
構成図と選定した技術
既存のLambda関数とは別でBedrock AgentCore Runtimeを外に出しました。

ToolとしてYouTube検索ができるように、GoogleCloudで Google YouTube Data API を使えるようにしました。本当は他にも最初にGoogle Custom Search のAPIも使えるように設定したのですが、諸事情で外しました(後述します)
なぜこの設計構成にするのか?
-
コストを最小化したい
そもそもサーバレス構成なので未使用時には金額がかからないというメリットはあります。しかし生成AI利用料金は別途かかります。
今回利用するAWS環境はAWS認定インストラクターとしてクレジットを沢山もらったので、クレジットで利用料金を相殺できるKimiをスーパーバイザーとして選定しました。
ただ全ての処理をKimiに指定すると結果がイマイチな部分があったので、文章理解や生成などについてはClaude Haiku 4.5を使うようにしました。
-
AIエージェント機能を将来簡単に切り替えしたい
そもそも既存のLambda関数をまるっとAgentCore Runtimeに移行するのも考えたのですが、将来AIエージェントサービスが他にも出てくることを予想して、既存のLambda関数は残す。
その残したLambda関数が、各種AIエージェントサービスを呼び出す構成にすれば切り替えしやすくなるなと考えた次第です。
-
プロンプトや思考プロセスをコントロールしたい
これも大事ですね。思考プロセス(Chain of Thought)を自分で完全にコントロールしたかったです。
推しを支援するキャラクターの挙動はブラックボックス化したくなかったです。
プロジェクト構成
今回もCDK使って実装しました。ほんとCDK便利ですよね
├── agentcore_entrypoint.py # AgentCore Runtime エントリーポイント├── src/│ ├── supervisor_agent.py # Supervisor Agent (Strands Agent)│ ├── action_group_handler.py # ツールルーティング & Lambda ハンドラー│ ├── models/schemas.py # Pydantic モデル定義│ ├── tools/│ │ ├── youtube_search.py # YouTube検索ツール│ │ └── translation.py # 翻訳ツール│ └── utils/│ ├── response_validator.py # レスポンスバリデーション│ └── secrets.py # Secrets Manager クライアント├── cdk/ # CDK スタック (Lambda, IAM, Secrets Manager)├── tests/ # テスト (unit / property / integration)├── scripts/ # ローカル・クラウドテストスクリプト└── requirements.txt # AgentCore デプロイ用依存関係
ちなみにAgentCore Runtimeはコンテナ環境で動くのですが、ローカルPCにDockerはインストールしたくなかったので、bedrock-agentcore starter toolkitを使いました。
https://github.com/aws/bedrock-agentcore-starter-toolkit
キャラクターロジックの検証
推し活において重要なのは対象へのリスペクト(キャラクター性の維持)です。生成AIが生み出した言葉をボットが発言する際に「AIが勝手にやったことだから」では大変です。
よって生成AIが毎回違う事を言わないようにある程度制御することにしました。愛の契約書です♪
class AgentResponse(BaseModel):
content: str
@field_validator('content')
@classmethod
def validate_character_tone(cls, v: str) -> str:
# キャラクターのアイデンティティである語尾を強制
if not v.endswith("イモ🍠"):
raise ValueError("Character violation: Sentence must end with 'イモ🍠'")
# Markdownの誤用を防ぐ(Bot投稿時の表示崩れ防止)
forbidden_chars = ['#', '**', '```']
if any(c in v for c in forbidden_chars):
raise ValueError(f"Format violation: Contains forbidden markdown characters")
return v
語尾に「イモ🍠」をつけるの徹底です。あとMarkdown形式も出さないように指定してます。
リトライ処理による再教育
バリデーションエラーが発生した場合、単にエラーを返して終了するのは不親切です。
そこで、エラー内容を生成AIにフィードバックして、「何がいけなかったのか」を理解させて再生成させるSelf-Correction Loopを構築しました。
これにより、一時的な不整合をエージェント自身が自動修復します。
# リトライ時のプロンプト注入例
retry_prompt += (
f"\\n\\n⚠️ 前回の出力はバリデーションエラーでした。"f"違反内容: {', '.join(violations)}。""上記の制約を厳守して再生成してください。"
)
Google Custom Search APIの利用不可
実は結構前にGoogle検索もAPIで利用していたことがあったので、今回のBedrock AgentCoreでもGoogle検索が使えるようにしようと考えてました。
しかしGoogle側が制限を始めて最近ではすでに使えなくなっていました(悲しい)。
良かった点と問題点
これで自律的にボットが色々動いてくれるようになりました。
以下、実装してみて良かった点と問題点の列挙です。
金額が神!AWS側はほとんどお金がかからない
これは本当にありがたいです。ちゃんと動くのにAWS側の利用料金は皆無に等しいです。
最初まったく課金されなくてビビってダッシュボード作って動作確認したほどです。しかもAWS認定インストラクター特典でもらえるAWSクレジットで相殺される部分もあるのでほんと助かります。

毎日運用しても$0.085以下です。
しかもそれがAWSのクレジットと相殺するので実課金はほとんどありません。ほんと助かる!
AWS側のチューニング対応は?
サーバレスだから未使用時には安いといってもちゃんとチューニングは必要だと思ってます。今回は以下3つやりました。
-
Lamda のメモリ調整
呼び出しする側のLambda関数ですが最初は512MBでメモリ量を設定していたのですが、256MBに減らしました。そんなに差がなかったので今のところ落ち着いてます。
-
タイムアウト設定
いやぁそんなに300秒またなくてよいでしょ。なんならリアルタイム性はX投稿では皆無なのでバッチ処理したいと思うぐらいだったので、タイムアウトは120秒にしました。
-
翻訳部分のトークンを減らした
翻訳処理をするツールの max_tokens を2048から512に制限しました。
変にまどろっこしい冗長な出力を物理的にぶったぎってキレのあるX投稿文を作成する勢いです。
XのAPI料金が高すぎる問題
AWS側のコスト部分は特に問題なく解決できたのですが、問題はX側のAPI料金の高さです。
https://developer.x.com/#pricing

読み取り1リクエストが$0.005、ポスト投稿が$0.01ですか!
流石に高いので全件検索や処理などは行わずに差分だけを処理するようにDynamoDBのテーブルで処理済のXポスト番号などを控えるようにしました。
しかし調べてみるともっとコスト効率の良いロジックができそうなので、XのAPI処理部分は今後もチューニングする予定です。
まとめ
お陰様で全自動で色々自律的に動き始めて、予想外のX投稿もしてくれるようになりました。
驚いたのは、まったく見たことがない推しのYouTube動画を探し出してポストした件です。なにそれ?!あなたどうやってそれ探し出してきたのよ?ってびっくりです。
今後やりたいこと
私はAWSに限らず、「いろんな技術を触って楽しむ派会長」なので、他のクラウドプロバイダーでも同様なージェントを複数準備して以下試してみたいと考えています。
- 他のAIエージェントの切り替えをやってみる or マギシステムみたいに複数AIエージェントで協議させる
- AWSだったら、DynamoDB とか AgentCore Memoryなどを使って推しの情報を長期記憶させる
いろいろと夢が広がりますね🍠
以上、Amazon Bedrock AgentCore Runtime で構築する"愛"のサーバレスアーキテクチャ解説記事でした!
AIエージェント、生成AI関連のAWS研修
せっかくなので、今回の記事テーマに関連するAWS研修を2つご紹介します!
▼AI エージェントを活用した課題解決を目指している方に!Agentic AI Foundations
AWSサービスを使用してエージェントAIシステムを設計するための基本原則と戦略を学びます。
従来の対話型システムとエージェントAIの違いを理解し、Amazon Q、Kiro、Amazon Bedrock Agents、Amazon Bedrock AgentCore などのツールを使用して、実際の問題を解決する自律的で目標駆動型のソリューションを構築する方法を学習します。
▼ 生成AIのビジネス活用に向けた総合的なスキルを習得!Advanced Generative AI Development on AWS
AWS 上で組織のニーズやビジネス目標に沿った生成 AI ソリューションを企画・設計・実装するための体系的な知識と実践手法を学びます。基礎モデルの理解から、エンタープライズシステムとの統合パターン、ベクトルデータベースを用いた検索拡張生成(RAG)の実装までを段階的に学びます。
もちろん、その他のAWS研修も多数ご用意しています。下記のご紹介もぜひご覧ください。
トレノケートのAWS研修で、学びを実践力に変える
トレノケートの AWS認定トレーニング では、AWS社の厳格な基準を満たした認定講師が、体系的かつ実践的な学習をサポートします。
基礎から応用、そして認定資格取得まで。
目的やレベルに応じて最適なコースをお選びいただけます。
AWSの基本を知りたい方や、AWSについて詳しく知りたいという 方は、弊社のAWS認定インストラクターが解説するこちらの記事がおすすめです。
▶「 AWSとは?AWS認定講師が解説」 を確認する
体系的な学びを通じて、AWSを“理解する”から“使いこなす”へ。
トレノケートは、皆さまのクラウドスキル成長を全力でサポートします。























