

【解説つき】G検定の例題を解いてみよう
こんにちは。トレノケートマーケティング部の小山です。今日もひっそり活動しています。
AI関連の認定として注目が高まっている「G検定(JDLA Deep Learning for GENERAL)」。一般社団法人日本ディープラーニング協会の公式Webサイト(外部リンク)では、その例題が公開されています。
例題といっても基本的なものから難易度高めのものまで用意されていて、試験前の練習にはちょうど良い内容になっています。私も「G検定(JDLA Deep Learning for GENERAL 2019 #2)」を受験・合格した際にはこの例題を理解度チェックに活用しました。
ただ、正解は残念ながら非公開なのですね。
というわけで今回は、例題をいくつか解いてみました。G検定の試験勉強の参考になれば幸いです。
▼【お知らせ】ダウンロード無料!AI入門資料▼
AIの概況や機械学習の分野で飛び交う概念や用語を簡潔に解説した小冊子を無料プレゼント!
詳細・ダウンロードはこちらから
※例題の引用元:一般社団法人日本ディープラーニング協会のWebサイト より引用(外部リンク)
※情報は2019年10月時点のものです。
※更新:
- 2023年2月8日:おすすめトレーニングにビジネスパーソンのためのAIリテラシー入門 ~G検定対応~を追記しました。
- 2021年6月9日:<1>人工知能の歴史に関する問題 選択肢の変更について追記しました。
目次[非表示]
- 1. G検定とは?
- 2. G検定例題の解答と解説
- 2.1. <1>人工知能の歴史に関する問題
- 2.2. <2>機械学習の手法に関する問題
- 2.3. <3>ディープラーニングの概要・手法に関する問題
- 3. 【無料ダウンロード】小冊子「サクッと分かるAIはじめの一歩」
- 4. AI人材育成トレーニング/eラーニング
G検定とは?
G検定とは一般社団法人日本ディープラーニング協会の認定です。
・概要:ディープラーニングを事業に活かすための知識を有しているかを検定する
・試験概要:120分、小問226の知識問題(多肢選択式)、オンライン実施(自宅受験)※一般社団法人日本ディープラーニング協会のWebサイトより引用(外部リンク)
※2019年10月時点
公式サイトの情報※によれば、2017年の開始から受験者は年々増加していて、2019年に実施された2回の試験の合格率は7割程度です。
問題数の多さ・範囲の広さから、準備は結構大変ですが、合格そのものの難易度はそこまで高くはない印象です。努力がしっかり報われる類の試験だと思います。
G検定の詳細については下記記事もぜひご参照ください。
G検定とは?難易度やおすすめの勉強法、取得のメリットなど
※参考:「G検定(ジェネラリスト検定)2019 #2」結果発表(外部リンク)
G検定例題の解答と解説
それでは、G検定の例題に挑戦してみましょう。
<1>人工知能の歴史に関する問題
◆問題:以下の文章を読み、空欄に最もよく当てはまる選択肢をそれぞれ1つずつ選べ。
第一次AIブームは1950年代に起こった。この頃に人工知能と呼ばれたプログラムは(ア)をもとに問題を解いていた。特に、1996年にIBMが開発した(イ)は、チェスの世界チャンピオンであるガルリ・カスパロフに勝利したことで有名である。しかし、ルールや設定が決まりきった迷路やパズルゲームなどの(ウ)と呼ばれる問題しか解けないという課題があったために、研究は下火になった。
(ア)の選択肢
1)知識表現、2)表現学習、3)機械学習、4)探索・推論(イ)の選択肢
1)Deep Blue、2)Bonkras、3)Ponanza、4)Sharp(ウ)の選択肢
1)A/Bテスト、2)パターンマッチング、3)トイ・プロブレム、4)逆問題
解答:(ア)4)探索・推論、(イ)1)Deep Blue (ウ)トイ・プロブレム
【解説】
第一次AIブームは「推論・探索」を元に問題を解くAIの研究が進んだ時代です。
IBMが開発したチェス専用のプログラム「Deep Blue」は、機械が人間に勝利したということで注目を浴びました(ちなみに選択肢2)Bonkras 、3)Ponanzaは、コンピューター将棋のソフトウェア)。
DeepBlueのような劇的な成果もありましたが、それでも「推論・探索」による手法では明確なルールのあるゲームのような問題(トイ・プロブレム、おもちゃの問題)は解ける一方で、現実世界の複雑な問題への対応は難しく、第一次AIブームは終焉を迎えました。
◆問題:以下に挙げる用語は、第二次AIブームが起こった際に取り上げられた問題である。
それぞれの問題の説明としてふさわしいものをそれぞれ1つずつ選びなさい。
(ア)フレーム問題 (イ)シンボルグラウンディング問題
1) 人間の持つ膨大な知識を体系化することが難しい。
2)有限な情報処理能力では、 知識を用いて現実のあらゆる問題を解くことは難しい。
3)単語の文字列などの記号と、それの表す意味を結びつけることが難しい。
4)膨大な知識を処理するための高速な計算機の開発が難しい。
5)十分なデータを取るためのインターネットを整備することが難しい。
解答:(ア)2)有限な情報処理能力では、 知識を用いて現実のあらゆる問題を解くことは難しい
(イ)3)単語の文字列などの記号と、それの表す意味を結びつけることが難しい。
【解説】
(ア)フレーム問題とは、「コンピューターにはある問題を解くために、必要な知識だけを取り出して使うことが困難」という問題です。ダニエル・デネットはこの問題を、「洞窟からバッテリーと爆弾を取り出すロボットのたとえ」で説明しています。
ロボットのバッテリーが洞窟の中にあり、なんとその上には時限爆弾が。
なんでそんな状況なのかは小一時間くらい問い詰めたいところですがそれはさておき、ロボット君は、洞窟から自分のバッテリーを取って来ないといけません。
人間ならば、「洞窟に入って、さっとバッテリーだけ持ってくればいいよね」ということは瞬時に判断できそうです。しかし、これをロボットにこのタスクをやらせてみると、爆弾もセットで持ってきてしまったり、不必要なことまで考えすぎてバッテリー切れ&時限爆弾でタイムオーバーになってしまったりして上手くいかない……と、概要はこのような話です。
このロボットのように必要な情報の取捨選択ができず、全てのケースを計算して課題を解くとなると、現実的な問題に対処するのはとうてい難しいということで、この例題の選択肢の中で一番近いのは、2)だと考えられます。
(イ)シンボルグラウンディング問題とは、「コンピューターには単語と意味を結び付けて理解するのが困難」であるという問題です。
人間は単語と意味を結び付けて理解しているため、例えばシマのある馬を見て「あれが世に聞くシマウマかな」とか、白いクマを見て「あれがいわゆるシロクマかしら」とか、桃の枝をちょっきり切るゾウムシを見て「ひょっとしてあれが、モモチョッキリゾウムシなんじゃない?」といった認識や推察ができます。
一方コンピューターは単語と意味を結び付けて理解しているわけではないので、そうした認識はできません。よって正解は3)となります。
(2021年6月9日追記)
こちらの問題の選択肢が下記に変わっていました。
1. 人間の持つ膨大な知識を体系化することが難しい。
2. 膨大な情報のうちから、必要なものだけを選んで考慮することが難しい。
3. 単語などの記号と、それの表す意味を結びつけることが難しい。
4. 膨大な知識を処理するための計算機の開発が難しい。
5. 十分なデータを取るためのインターネットを整備することが難しい。
※一般社団法人日本ディープラーニング協会のWebサイトより引用(外部リンク)
より分かりやすい選択肢になっていますね。
解答はこのようになると考えられます。解説は上記の通りです。
(ア)フレーム問題
→ 2. 膨大な情報のうちから、必要なものだけを選んで考慮することが難しい。
(イ)シンボルグラウンディング問題
→ 3. 単語などの記号と、それの表す意味を結びつけることが難しい。
<2>機械学習の手法に関する問題
◆問題:空欄に当てはまる語句の組み合わせとして最も適しているものを1つ選べ。
教師あり学習の問題は出力値の種類によって、大きく2種類に分けられる。
(A) 問題は出力が離散値であり、カテゴリーを予測したいときに利用される。
一方、(B) 問題は出力が連続値であり、その連続値そのものを予測したいときに利用される。
1. (A) 限定 (B) 一般
2. (A) 部分 (B) 完全
3. (A) 分類 (B) 回帰
4. (A) 線形 (B) 非線形
解答:3. (A) 分類 (B) 回帰
【解説】
「分類」はあらかじめ設定されたカテゴリにデータを分けたい、つまりカテゴリ(離散値)を予測したい時の手法で、「回帰」は、データから何らかの数値(連続値)を予測したい時の手法です。
■分類・・・カテゴリ(離散値)を予測 例:画像分類、スパム判定など
■回帰・・・数値(連続値)を予測 例:売上予測、家賃予測など
なお、「分類」は教師なし学習の「クラスタリング」と混同しないように違いをおさえておくことをオススメします。
ポイントは、「正解=分析者側で事前に用意したクラス分けがあるか否か」です。
教師あり学習の分類は、あらかじめ用意したクラスにデータを分ける手法で、教師なし学習の「クラスタリング」は、データの構造から自動的にクラスタ(まとまり)を導き出すという手法です。
◆問題:以下の空欄に最もよく当てはまる選択肢を1つずつ選べ。
分類問題にはさまざまな性能指標がある。
ここでは、サンプルを陽性(Positive)と陰性(Negative)の2クラスに分ける2値分類を考える。
(ア)は単純にサンプル全体のうち、予測が正解したサンプル数の比を取ったものである。
また、偽陽性(False Positive, FP)を減らすことを重視する場合には(イ)を、逆に偽陰性(False Negative, FN)を減らすことを重視する場合には(ウ)を採用することが望ましい。しかし、この両者はトレードオフの関係にあることから、それらの調和平均を取った(エ)が利用されることも多い。
1) 正答率、2)実現率、3)協調率、4)調和率、5)適合率 6)再現率、7)f値、8)p値、9)t値、10)z値
解答:(ア)1)正答率、(イ)5)適合率、(ウ)6)再現率、(エ)7)f値
【解説】
モデルの性能を測る評価指標と混合行列の問題ですね。
混合行列とは、テストデータに対するモデルの予測結果を、真陽性・真陰性・偽陽性・偽陰性の4つに分類した表です。
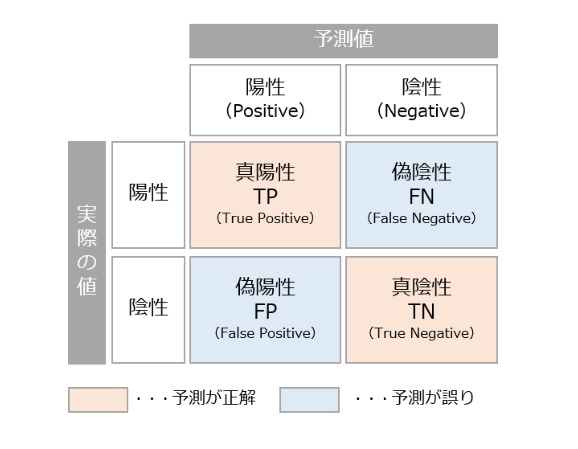
この話、真陽性とか偽陰性とか、なんかややこしいというか、「どれがどれだっけ?」と混乱しませんか?私は結構苦手でしたが、下記のように文字を分解して考えると、スッと頭に入りました。

その他の3つの定義は下記のとおりです。
・真陰性 = 陰性だと予測して、正解(実際も陰性)
・偽陰性 = 陰性だと予測して、誤り(実際は陽性)
・偽陽性 = 陽性だと予測して、誤り(実際は陰性)
この混合行列をふまえたモデルの評価指標には、
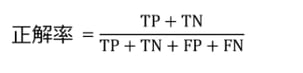
正答率(正解率)・適合率・再現率・F値があります。それぞれ下記のような式になります。
■正答率(正解率)=全データのうち、予測が当たった割合
■適合率=予測が陽性だった中で、実際に陽性だった割合

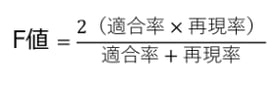
■再現率= 実際に陽性だったケースを正しく予測できた割合

■F値=適合率と再現率の調和平均
正解率は、単純に「全テストデータのうち予測が当たった割合」ということで、分かりやすい指標ではありますが、データの偏りが著しい場合に指標として適切かどうかという問題があります。
例えば「異物混入の発見」や「病気の判定」など陽性まれで陰性が多数の場合、陰性の予測が当たりやすくなり正解率は高くなりますが、陽性を正しく判定したい場合の評価指標としては不適切です(具体例は下記、「再現率を意識するケースの例」をご参照ください)。
そこで、評価指標には適合率や再現率、その両方を考慮したf値が用いられます。
適合率は予測の精度を高めたいときの指標(=偽陽性を低くしたい)として使用され、再現率は、疾病判定などの陽性を見逃してはならないようなケース(=偽陰性を低くしたい)で使用されます。
問題文にあるように、適合率と再現率は、一方を高めると一方が低くなるという関係にあるため、両方の値を考慮したF値が利用されることも多いです。
●参考:再現率を意識するケースの例
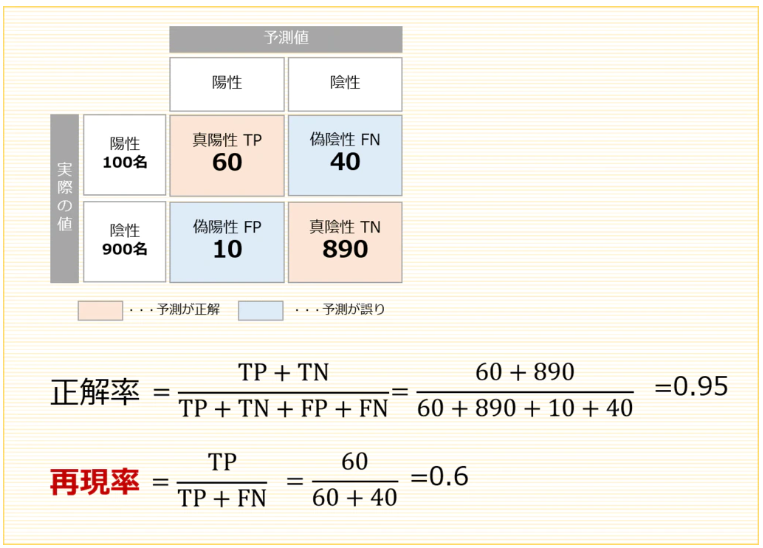
例えば、ある病気にかかっているかどうかを判定したい(TP=病気が陽性)とします。
サンプル数1,000人のうち、実際に病気が陽性だったのは100名。
この100名のうち、陽性判定がでたのは60名だった、というケースを考えます。
この場合、実際に病気にかかっている人のうち4割は誤診となっていますが、
正解率を計算すると、なんと95%になります。一方、再現率は60%となります。
このケースのように、陽性の見逃し、つまり誤って陰性と判定する偽陰性(FN)を低く抑えたい場合は、再現率を採用します。
◆以下の文章は、さまざまな機械学習の手法について述べたものである。空欄に最もよく当てはまる選択肢を、語群の中から1つずつ選べ。
学習データに教師データと呼ばれる正解ラベルつきのデータを用いる手法は(ア)と呼ばれ、対照的に正解ラベルがないデータを利用する手法は(イ)と呼ばれる。また、正解ラベルが一部のサンプルにのみ与えられている(ウ)という手法も存在する。
1)教師なし学習
2)教師あり学習
3)強化学習
4)表現学習
5)マルチタスク学習
6)半教師あり学習
7)多様体学習
解答:(ア)2)教師あり学習、(イ)1)教師なし学習、(ウ)6)半教師あり学習
【解説】
機械学習のうち、正解ラベルつきのデータを用いる手法は「教師あり学習」です。
予測が正解ラベルに近づくように学習を行います。あらかじめ設定したグループに分ける「分類(例:画像識別など)」と、出力値を予測する「回帰(例:売上や家賃の予測など)」があります。
一方、正解ラベルのない手法は、「教師なし学習」と呼ばれています。こちらはデータの法則性やまとまりを導き出したい時(=クラスタリング)、多次元のデータをより低い次元に圧縮したい(=次元削減)時に用いられます。
なお、一部のデータのみに正解ラベルがある手法は「半教師あり学習」と呼ばれています。
<3>ディープラーニングの概要・手法に関する問題
◆あるニューラルネットワークのモデルを学習させた際、テストデータに対する誤差を観測していた。そのとき、学習回数が100を超えるまでは誤差が順調に下がり続けていたが、それ以降は誤差が徐々に増えるようになってしまった。その理由として最も適切なものを1つ選べ。
1)学習回数が増えるほど、誤差関数の値が更新されにくくなるため。
2)学習回数が増えるほど、学習データにのみ最適化されるようになってしまうため。
3)学習回数が増えるほど、一度に更新しなければならないパラメータの数が増えていくため。
4)学習回数が増えるほど、計算処理にかかる時間が増えてしまうため。
解答:2)学習回数が増えるほど、学習データにのみ最適化されるようになってしまうため。
【解説】
機械学習では、学習データに対する予測の誤差(訓練誤差)は小さいにもかかわらず、テストデータでの予測の誤差(=汎化誤差)は小さくならないことがあり、これを「過学習」と呼びます。モデルが学習データにのみ最適化され、未知のデータに対する精度が落ちているという状態です。
過学習の対策としては、正則化・ドロップアウト・Early Stoppingといった手法があります。
- 正則化
誤差関数にモデルの重みがとり得る値の範囲を制限する項(正則化項)を追加することで、モデルが複雑になりすぎることを防ぐ - ドロップアウト
ランダムにニューロンを非活性化することで、毎回異なるネットワークで学習を行う。 - Early Stopping(早期打ち切り)
誤差関数の値が上がり始めた時点で学習を止める
◆問題:以下の文章を読み、空欄に最もよく当てはまる選択肢を語群の中から1つずつ選べ。
画像認識の国際的なコンペティションのひとつに、ILSVRC(ImageNet Large Scale Visual Recognition Competition)がある。ここで、2012年にCNNのモデルである(ア)が優勝を飾った。
それからというもの、続けざまにCNNのモデルが高い成果を上げている。2014年にはインセプションモジュールという構造を利用した(イ)が優勝し、オックスフォード大のチームが開発した(ウ)もまたそれに迫る優秀な成績を収めた。また、2015年には残差学習という深いネットワークの学習を可能にした(エ)がそれぞれ優勝している。
1)AlexNet、2)ElmanNet、3)GoogLeNet、4)ImageNet、5)LeNet
6)ResNet、7)VGG16、8)WaveNet
解答:(ア)1)AlexNet、(イ)3)GoogLeNet、(ウ)7)VGG16、(エ)6)ResNet
【解説】
画像認識のコンペティション「ILSVRC」で有名な出来事は下記のとおりです。
- 2012年:ジェフリー・ヒントン率いるトロント大のモデル「AlexNet」が優勝。第三次AIブームのきっかけに。
- 2014年:GoogLeNetが優勝、VGG16が準優勝。
- 2015年:ResNetが優勝。
◆問題:以下の文章の空欄に最も適切に当てはまる選択肢を、各語群の中からそれぞれひとつずつ選べ。
ロボティクス分野でも、機械学習の応用が進められている。例えば、ロボットの動作制御にQ学習やモンテカルロ法などを用いる(ア)のアルゴリズムを利用する事例は多く存在する。また、ロボットはカメラ(視覚)、マイク(聴覚)、圧力センサ(触覚)などの異なったセンサ情報を収集できる(イ)システムを持っていることから、これらの情報をDNNで統合的に処理する研究や、ロボットの一連の動作の生成をひとつのDNNで実現しようとする(ウ)の研究も行われている。
・選択肢ア)
1) 一気通貫学習 2)教師あり学習 3)挙動学習 4)適応的学習 5)強化学習 6)表現学習
・選択肢 (イ)1)マルチモーダル 2)インセプション 3)コグニティブ 4)フルスクラッチ
・選択肢 (ウ)1)一気通貫学習 2)教師あり学習 3)挙動学習 4)適応的学習 5)強化学習 6)表現学習
解答:(ア)5)強化学習、(イ)1)マルチモーダル、(ウ)1)一気通貫学習
【解説】
ロボティクスの分野では、Q学習やモンテカルロ法などを用いる「強化学習」のアルゴリズムの利用が進んでいます。
ロボットは、視覚や聴覚など複数の感覚の情報をまとめて収集できる「マルチモーダルシステム」を持っています。
ロボットの一連の動作を一つのDNNで実現する試みは「一気通貫学習」と呼ばれています。
以上、いかがでしたでしょうか。
G検定の理解度チェックとしては、例題がある程度分かる状態を目安の一つにすると良いかと思います(正解と解説が公式に公開されていると良いのですが……)。
G検定の合格を目指す皆さまの参考になれば幸いです!
【無料ダウンロード】小冊子「サクッと分かるAIはじめの一歩」
AIの基礎がサクッとわかる小冊子を無料プレゼント。
AIの概況や機械学習の分野で飛び交う概念や用語を簡潔にご紹介します。
▼詳細はこちらから▼

AI人材育成トレーニング/eラーニング
AI人材の争奪戦が激しさを増す中、社内におけるAI人材育成の重要性が高まっています。
トレノケートでは人工知能の基礎知識、機械学習、ディープラーニング関連コースを提供しています。
▼おすすめのeラーニング:AIに必要な数学を高校数学から学ぶ
[ASP]データ分析シリーズ1 AI数学 ~文系でも理解できる!高校から始めるデータ分析、AIのための数学~
高校数学からデータ分析、機械学習に関わる数学を学習したい方向け。初心者でもつまずかずに学習できるよう数学に特化して構成しています。
▼おすすめトレーニング:AIの基本を1日で学ぶ
ビジネスパーソンのためのAIリテラシー入門 ~G検定対応~
AIに関する知識を、コンパクトに1日で学ぶことができる研修です。 デジタルリテラシーとしてAIの基礎知識を身につけたい方や、G検定受験に向けてのファーストステップに最適です。
【学習目標】
● AIやディープラーニングがどのようなものか説明できる
● 教師あり学習、教師なし学習、強化学習の概要を説明できる
● ディープラーニングの概要と応用分野を説明できる
● AIプロジェクトについて概要を説明できる
→ コース詳細・日程はこちら
マシンラーニングオーバービュー ~AIを支える技術・理論・利用方法を学ぶ~
機械学習が何なのか、どのように動いているのか、導入・利用するには何が必要なのか、ということを1日で効率的に学習することができます。
【学習目標】
● 機械学習の概要を理解する
● 機械学習のアルゴリズムと要素技術の概要を理解する
● 機械学習の実装方法と利用方法を理解する
→ コース詳細・日程はこちら
▼そのほかのAI人材育成トレーニングはこちらから
























